DNA, RNA and protein synthesis (A-level biology)

Nature of the Gene and protein synthesis
Specific objectives
- Describe the composition of chromosomes and the structure of nucleotides
- Describe the structure of DNA and RNA
- Distinguish between DNA and RNA
- Explain the Watson Crick hypothesis of the nature of DNA
- Explain DNA replication.
- Describe the nature of the gene
- Describe the structure of the genetic code
- Describe the formation of RNA
- State the role of DNA and RNA in protein synthesis. Describe protein synthesis.
Gene
This is a segment of DNA that tells the body how to produce specific proteins – contain the genetic information that is passed from parents to their offspring. These genes are found in structures called chromosomes, which are passed to the embryo during conception. Because the DNA passed from one human to another helps determine gender and physical characteristics, this nucleic acid is necessary for the survival of the species.
Evidence that DNA is the hereditary material
1. DNA is a stable molecule
2.. The amount of DNA in a given species is constant for all cells.
3. Mutation or changes in the composition of DNA alter the organisms’ characteristics.
4. Purified DNA rather than proteins from dead virulent bacterium Pneumococcus strain which causes pneumonia was shown to transform the non-virulent form into a virulent form. The ability of DNA to transform nonvirulent form was stopped by addition of an enzyme that breaks DNA in the dead virulent form before DNA was purified.
5. DNA rather than proteins of bacteriophage (T2 phage) that infect E. coli was shown to be the hereditary material because it enabled the E. coli to synthesize the new T2 phage viruses.
Nucleic acids
This is a form of genetic material in all living organisms including the simplest viruses. Nucleic acids are polymers made of subunits called nucleotides.
Types
1. Deoxyribonucleic acid (DNA) is found in the nucleus
2. Ribonucleic acid (RNA) is found in both the nucleus and cytoplasm.
A nucleotide is made up of three molecules:
(i) Phosphate group
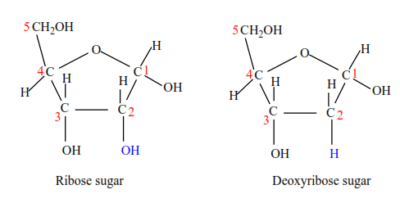
(ii)Pentose sugar – either Deoxyribose (in DNA) or Ribose (in RNA)
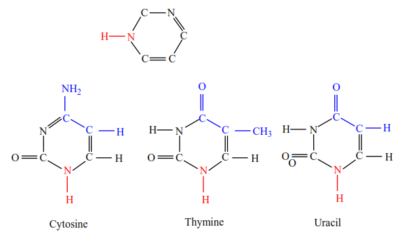
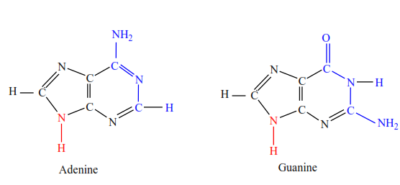
(iii) Nitrogen base – any purine (Adenine, Guanine) or pyrimidine (Cytosine and either Thymine in DNA or Uracil in RNA)
Structure of nucleotide
It is made of phosphoric acid, sugar and an organic base.
(a) Phosphoric acid


(b) Sugar: the pentose sugar in RNA is ribose while that of DNA is deoxyribose sugar. Deoxyribose sugar lacks an oxygen atom on the second carbon atom

(c) Organic Bases: DNA contains four different organic bases; adenine (A), guanine (G) cytosine (C) and thymine (T). RNA also contains adenine (A), guanine (G), cytosine (C) and Uracil (U). all these bases are ring compounds, made of carbon and nitrogen.
Pyrimidines (cytosine, uracil and thymine; CUT) have a six-membered ring.

Purine (Guanine and Adenine (GA) have a two membered ring)

Nucleoside forms when a pentose sugar joins an organic base by a condensation reaction (a water molecule is lost).
Nucleotide forms when a nucleoside (pentose sugar + organic base) joins a phosphate by loss of a second water molecule.

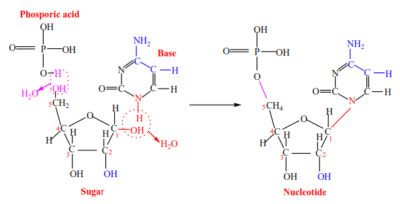
The sugar-phosphate-sugar backbone is formed when the 3’ carbon on one sugar joins to the 5’ carbon on the next sugar by phosphodiester bonds repeatedly to form a polynucleotide (a long chain of nucleotides) with organic bases protruding sideways from sugars.
Nitrogen base
DNA structure according to Watson and Crick
- DNA consist of two polynucleotide strands.
- The polynucleotide strands are antiparallel (face in opposite directions) i.e. one runs from 3’ to 5’ direction while another one runs from 5’ to 3’ direction.
- A DNA nucleotide is made up of three molecules:
- Phosphate group
- Deoxyribose sugar
- Nitrogen base – either adenine (A), guanine (G), thymine (T) or cytosine (C).
- Untwisted DNA is ladder-like, in which the sugar-phosphate backbones represent the handrails while the nitrogen base pairs represent the rungs.
- Twisted DNA forms a double helix of major and minor grooves.
- The sugar-phosphate-sugar backbone is held by covalent phosphodiester bonds, while the nitrogen bases from the two strands form weak hydrogen bonds by complementary base pairing i.e. A with T, C with G.

ADAPTATIONS OF DNA
(i) Sugar-phosphate backbone is held together by strong covalent phosphodiester bonds to provide stability.
(ii) The two sugar-phosphate backbones are antiparallel which enables purine and pyrimidine nitrogen bases to project towards each other for a complementary pairing.
(iii) Sugar-phosphate backbones are two / it is double-stranded to provide stability.
(iv) The two sugar-phosphate backbones form a double helix to protect bases/hydrogen bonds.
(v) Long/large molecule for the storage of a lot of information.
(vi) The double-helical structure makes the molecule compact to fit in the nucleus.
(vii) Base sequence allows information to be stored.
(vii) Double-stranded for replication to occur semi- conservatively/ strands can act as templates.
(viii) There are many hydrogen bonds that increase the stability of the DNA molecule.
(ix) There is complimentary base pairing / A-T and G-C for accurate replication/identical copies can be made;
(x) Weak hydrogen bonds enable unzipping /separation of strands to occur readily.
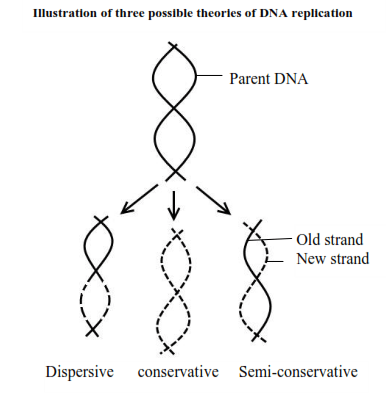
Theories of DNA replication
DNA replication is the process by which the parent DNA molecule makes another copy of itself.
1. Fragmentation hypothesis (Dispersive hypothesis)
The parent DNA molecule breaks into segments and new nucleotides fill in the gaps precisely.
2. Conservative hypothesis
This suggests that the DNA strands remain intact but in some way initiate the synthesis of new but exact copies of DNA to the parent DNA.
3. Semi-conservative hypothesis
The parent DNA molecule separates into its two component strands, each of which acts as a template for the formation of a new complementary strand. The two daughter molecules, therefore, contain half the parent DNA and half new DNA. The semi conservative hypothesis was shown to be the true mechanism by the work of Meselsohn and Stahl (1958) in their experiment on bacterium E.coli using radioactive 15N.

Necessities of DNA replication
- Free nucleotides to bond with complementary bases on the separated DNA strands.
- Energy source in the form of ATP
- Complementary DNA strand
- Enzymes such as DNA polymerase, DNA helicase and DNA ligase.
Steps of DNA Replication
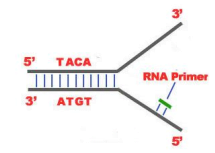
- DNA unwinds and then split open by a Helicase enzyme to expose the bases on either strand. An initiation point is a place rich in A-T probably because these are held by two hydrogen bonds as opposed to the three hydrogen bonds between C and G. The structure that is created is known as “Replication Fork“.

2. An enzyme RNA Primase bind to DNA at the initiation point and attracts the first nucleotide of the 3’-5’ strand

3. The elongation process involves the alignment of complementary nucleotides against the bases on open stands and then joined into new strands by the DNA polymerase. However, it occurs differently for the 5′-3′ and 3′-5′ template.
(a) 5′-3′ Template: The 3′-5′ proceeding daughter strand -that uses a 5′-3′ template– is called leading strand because DNA Polymerase ä can “read” the template and continuously adds nucleotides (complementary to the nucleotides of the template, for example Adenine opposite to Thymine etc.).
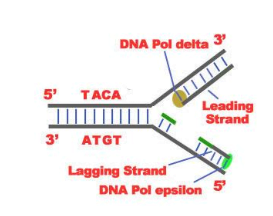
(b) 3′-5’Template: The 3′-5′ template cannot be “read” by DNA Polymerase ä. The replication of this template is complicated and the new strand is called lagging strand. In the lagging strand the RNA Primase adds more RNA Primers. DNA polymerase å reads the template and lengthens the bursts. The gap between the two RNA primers is called “Okazaki Fragments“.
The RNA Primers are necessary for DNA Polymerase å to bind Nucleotides to the 3′-5’ end of them. The daughter strand is elongated with the binding of more DNA nucleotides.

4. In the lagging strand the DNA Pol I –exonuclease– reads the fragments and removes the RNA primers. The gaps are closed with the action of DNA Polymerase (adds complementary nucleotides to the gaps) and DNA Ligase (adds phosphate in the remaining gaps of the phosphate – sugar backbone).
Each new double helix is consisted of one old and one new chain. This is what we call semiconservative replication.
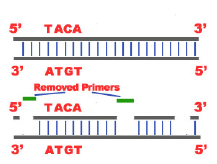
5. The last step of DNA Replication is Termination. This process happens when the DNA Polymerase reaches an end of the strands.
6. The DNA Replication is not completed before a mechanism of repair fixes possible errors caused during the replication. Enzymes like nucleases remove the wrong nucleotides and the DNA Polymerase fills the gaps.
The general structure of RNA
(a) RNA molecules are small/short, single-stranded (rRNA and mRNA) but maybe coiled around such that bases of the same strand pair with each other.
(b) RNA nucleotide is made up of three molecules:
(i) Phosphate group
(ii) Ribose sugar
(iii) Nitrogen base – either adenine (A), guanine (G), cytosine (C) or uracil (U)
(c) The sugar-phosphate-sugar backbone is held by covalent phosphodiester bonds.
(d) RNA occurs in three types whose sizes, shapes, amounts/abundance, and roles vary:
Types of RNA
1. Ribosomal RNA (rRNA)
Makes the highest percentage of RNA. It is a single strand with a double-helical region.
Its function are:
(i) an integral component to ribosome structure i.e when removed from the ribosome, ribosomes structure collapses
(ii) it serves as a temperate partner for the synthesis of ribosomal proteins
2. Messenger RNA (mRNA)
Forms 3-5% of the total RNA in a cell. mRNA carries coded information from DNA to ribosomes in the cytoplasm
3. tRNA
is an adaptor molecule composed of RNA, typically 76 to 90 nucleotides in length, that serves as the physical link between the mRNA and the amino acid sequence of proteins. tRNA does this by carrying an amino acid to the protein synthetic machinery of a cell (ribosome) as directed by a three-nucleotide sequence (codon) in a messenger RNA (mRNA). As such, tRNAs are a necessary component of translation, the biological synthesis of new protein in accordance with the genetic code.

Comparison of DNA and RNA
Similarities
Both:
(1) are polymers of nucleotides
(2) carry genetic information
(3) have same purine bases adenine and guanine plus pyrimidine bases cytosine
(4) originate from the nucleus
Differences
| Aspect | Deoxyribonucleic Acid (DNA) | Ribonucleic Acid (RNA) |
| Function | Stores genetic information for a long time and transmits it. | Transfers genetic code needed for the creation of proteins from the nucleus to the ribosome. |
| Structure |
Double-stranded. High molecular mass Pentose sugar is deoxyribose Quantity is fixed in a cell |
Single-stranded. Low molecular mass Pentose sugar is ribose Quantity is variable |
| Base Pairing | Organic bases are guanine, adenine, cytosine, and thymine | Organic bases are guanine, adenine, cytosine, and uracil |
| Location | Much of DNA is in the nucleus of a cell, little in mitochondria and chloroplasts. | Much of RNA is in the cytoplasm, little in the nucleus. |
| Stability | stable | less stable |
| Propagation | (xiii) DNA is self-replicating. | (xiii) RNA is synthesized from DNA when needed. |
| Unique Features | (xiv) DNA is protected in the nucleus, as it is tightly packed. | (xiv) RNA strands are continually made, broken down and reused. |
| Types | (xvii) Only two types: intranuclear and extra nuclear DNA | (xviii) Three different types: mRNA, tRNA and rRNA |
The central dogma of molecular biology
It states that DNA makes RNA makes proteins
PROTEIN SYNTHESIS
Protein synthesis is the process by which individual cells construct proteins. Protein synthesis occurs in separate but interrelated steps as follows:
1. Transcription
Transcription is the process whereby the DNA code of a gene is copied to make messenger RNA (mRNA).
Importance of transcription
- DNA is too large to fit through the nuclear pores, yet mRNA being small can readily exit the nucleus.
- DNA contains many codes that aren’t always needed at a given time, so m-RNA only carries that code needed to make specific proteins out of the nucleus to the ribosome.
Stages in transcription
- A specific region of DNA called a cistron unwinds to expose bases on each strand.
- Each base on one strand attracts its complementary RNA nucleotide, for example. a dree guanine base on DNA attracts an RNA nucleotide with cytosine and adenine attracts uracil.
- The enzyme RNA polymerase moves along the DNA adding one complementary RNA nucleotide at a time to a newly unwound portion of DNA.
- The region of base pairing between the DNA and RNA is only around 12 base pairs at a time as the DNA helix reforms behind the RNA polymerase.
- The DNA acts as a template against which mRNA is constructed.
Translation
This describes how the genetic code is converted into amino acids.
It occurs in three stages
The beginning step is called initiation, a middle step, called elongation, and a final step, called termination.
Initiation
During initiation, the mRNA, the tRNA, and the first amino acid all come together within the ribosome. The mRNA strand remains continuous, but the true initiation point is the start codon, AUG that specifies amino acid methionine. So, methionine is first the amino acid that is brought into the ribosome.
Elongation
The polypeptide chain grows by addition of amino acid; one at a time until a full polypeptide is done.
The mRNA shifts through the ribosome to expose a new codon that attracts the next tRNA with a matching anticodon.
A peptide bond forms between the two amino acids on the tRNA .
Termination occurs when all the codons on mRNA are read.
The ribosome reaches one or more stop codons on mRNA (UAA, UAG, UGA).
The ribosome detaches from the mRNA and splits into its small and large subunits, while the new protein floats away
Note:
- Several ribosomes can attach to a molecule of mRNA (to form polysomes/polyribosomes) one after another so that several proteins of the same type can be made from one mRNA at the same time.
- Newly synthesized proteins are packaged and sent to Golgi complex for modification/processing. This is called the post-translation processing of the protein.
Comparison between DNA replication and transcription
Similarities
Both:
(1) involve unwinding the helix
(2) involve separating the two strands
(3) involve breaking hydrogen bonds between bases
(4) involve complementary base pairing
(5) involve C pairing with G
(6) work in a 5` to 3` direction
(7) involve linking/ polymerization of nucleotides
(8) DNA or RNA polymerase require a start signal
Differences
| DNA replication | Transcription |
| Involves DNA nucleotides, where the pentose sugar is deoxyribose and the base adenine pairs with thymine | Involves RNA nucleotides where the pentose sugar is ribose and the base adenine pairs with uracil |
| Both strands are copied | Only one strand copied not both |
| Ligase enzyme / no Okazaki fragments are involved | No ligase enzyme / no Okazaki fragments |
| Has multiple starting points | Has only one starting point |
| replication gives two DNA molecules | whilst transcription gives mRNA |
Compare DNA transcription with translation
Both: (1) Occur in 5’ to 3’ direction (2) Require ATP
Differences
- DNA is transcribed while mRNA is translated
- Transcription produces RNA while translation produces polypeptides/ protein
- RNA polymerase for transcription while ribosomes for translation/ ribosomes in translation only
- Transcription occurs in the nucleus (of eukaryotes) while translation occurs in the cytoplasm/ at ER
- tRNA is needed for translation but not transcription
Explain briefly the advantages and disadvantages of the universality of the genetic code to humans.
(i) Genetic material can be transferred between species/ between humans
(ii)One species could use a useful gene from another species
(iii) Bacteria/ yeasts can be genetically engineered to make a useful product
(1) Viruses can invade cells and take over their genetic apparatus e.g. HIV
(2) Viruses cause disease
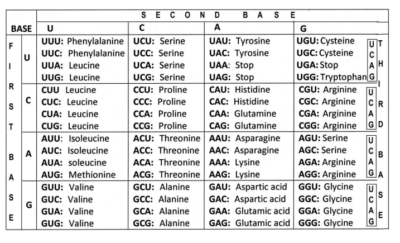
GENETIC CODE
The genetic code is the set of rules by which information encoded in genetic material (DNA or RNA sequences) is translated into proteins (amino acid sequences) by living cells.
THE GENETIC CODE CHART / TABLE

MOST IMPORTANT PROPERTIES OF GENETIC CODE
1. The code is a triplet codon
The nucleotides of mRNA are arranged as a linear sequence of codons, each codon consisting of three successive nitrogenous bases, i.e., the code is a triplet codon.
2. The code is non-overlapping
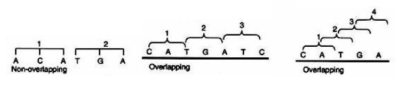

In translating mRNA molecules, the codons do not overlap but are “read” sequentially.
3. The code is comma less
This means that no codon is reserved for punctuation. After one amino acid is coded, the second amino acid will be automatically, coded by the next three letters and that no letters are wasted as the punctuation marks.
4. The code is non-ambiguous
A particular codon will always code for the same amino acid. The same codon shall never code for two different amino acids.
5. The code has polarity
The code is always read in a fixed direction, i.e., in the 5’→3′ direction.
6. The code is degenerate
More than one codon may specify the same amino acid; For example, except for tryptophan and methionine, which have a single codon each, all other 18 amino acids have more than one codon.
Biological advantages of degeneracy
- It permits essentially the same complement of enzymes and other proteins to be specified by microorganisms varying widely in their DNA base composition.
- It provides a mechanism of minimizing mutational lethality. E.g. Substitution of the third base-U in GUU (for valine) with C/A/G does not change the amino acid coded for.
7. Some codes are start codons
In most organisms, AUG codon is the start or initiation codon, i.e., the polypeptide chain starts either with methionine (eukaryotes) or N-formylmethionine (prokaryotes).
8. Some codes are stop codons
Three codons UAG, UAA and UGA are the chain stop or termination codons. They do not code for any of the amino acids. These codons are also called nonsense codons, since they do not specify any amino acid.
9. The code is universal
The same genetic code is found valid for all organisms ranging from bacteria to man.
For notes, questions and answers download PDF below
DNA, RNA and protein-synthesis
Sponsored by The Science Foundation College +256 753 80 27 09
Very good and precise notes best even for a verage learners
I really have liked the great work and effort you put in, it’s provided me with every information.
Perfect work
Thanks for providing such valuable insights. Office Products
You really have a way with words. Indian Cricket
Achieve your medical dreams with MBBS Direct Admission in Karnataka.
Immerse yourself in thrilling gameplay with Raja Luck Game.
Struggling to rank greater? Increase website backlinks with proven strategies.
Grab the best Play Store deals by using the latest 100 Google Play redeem code.
Get access to top-tier hardware with flexible Server Rental in Noida that fits your budget plan.